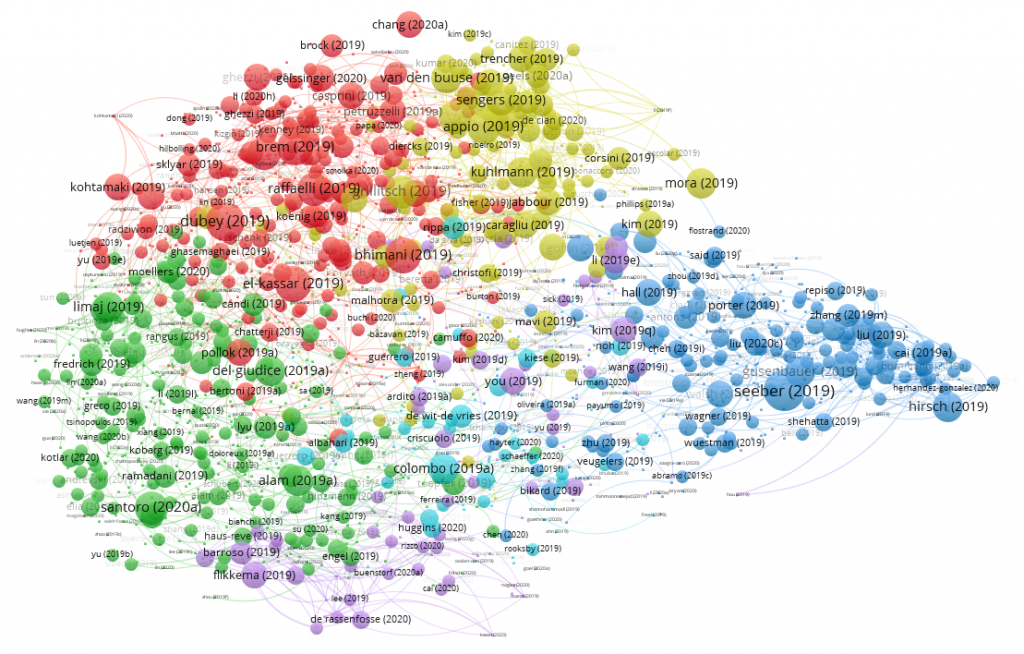
I wanted to get updated with the latest trends in the technology management literature. To do this, I conducted a bibliometric review of the publications in the top innovation and general management journals.
Journals Analyzed
I searched the Web of Science for articles published from 2019 in the top technology journals (Research Policy, Journal of Product Innovation Management, Technovation, Technological Forecasting and Social Change, R & D Management, Technology Analysis & Strategic Management, Journal of Engineering And Technology Management, Industry and Innovation, Research-Technology Management, Scientometrics and Journal of Technology Transfer). I then added articles in the top general management journals as long as they contain the terms science, technology or innovation. These journals include Administrative Science Quarterly, Academy of Management Journal, Academy of Management Annals, Academy of Management Review, Academy of Management Perspectives, Journal of Business Research, British Journal of Management, Journal of Business Venturing, Journal of Management Studies, Entrepreneurship Theory and Practice, Strategic Management Journal, Management Science, Strategic Entrepreneurship Journal, Journal of Management and Organization Science.
Using these data collection steps, I had 2,561 articles. I used python to analyze the articles in bulk. Visualizations were carried out using VosViewer.
Top Cited Works
Title
First Author
Journal
Year
Internal Citations
Self-citations as strategic response to the use of metrics for career decisions
Seeber, M
Res Pol
2019
9
Can big data and predictive analytics improve social and environmental sustainability?
Dubey, R
TFSC
2019
8
Social media and innovation: A systematic literature review and future research directions
Bhimani, H
TFSC
2019
7
How crowdfunding platforms change the nature of user innovation – from problem solving to entrepreneurship
Brem, A
TFSC
2019
7
Green innovation and organizational performance: The influence of big data and the moderating role of management commitment and HR practices
El-Kassar, AN
TFSC
2019
7
Understanding Smart Cities: Innovation ecosystems, technological advancements, and societal challenges
Appio, FP
TFSC
2019
6
Servitization and Industry 4.0 convergence in the digital transformation of product firms: A business model innovation perspective
Frank, AG
TFSC
2019
6
Technology Reemergence: Creating New Value for Old Technologies in Swiss Mechanical Watchmaking, 1970-2008
Raffaelli, R
ASQ
2019
6
Innovation policy for system-wide transformation: The case of strategic innovation programmes (sips) in Sweden
Grillitsch, M
Res Pol
2019
6
Collaborative modes with Cultural and Creative Industries and innovation performance: The moderating role of heterogeneous sources of knowledge and absorptive capacity
Santoro, G
Technovation
2020
6
Implementing citizen centric technology in developing smart cities: A model for predicting the acceptance of urban technologies
Charting a Path between Firm‐Specific Incentives and Human Capital‐Based Competitive Advantage – firms can offer unique incentives to their employees (e.g. Disney parks’ discount to employees, Google enabling employees access to interesting data, having a culture of fun at Zappos ). The paper provides a typology of these different incentives that can be unique to certain firms.
Scale quickly or fail fast: An inductive study of acceleration – accelerators have three main characteristics: investment on ventures that already reached product-market fit, focus on growth (through revenue, number of customers and even team maturity) in a short amount of time and an emphasis on aggressively testing whether the venture can succeed or fail.
Detecting academic fraud using Benford law: The case of Professor James Hunton – Benford’s law states that the first digit of datasets collected would likely to be small. For instance, the number 1 appears 30% of the time if a dataset if collected truthfully. The researchers used this idea to see whether they can detect the fraud from retracted papers.
Crossing the valley of death: Five underlying innovation processes – They describe five processes to cross the so-called valley of death, hindering early-stage ventures from succeeding. These include: refining the narrative for the technology concept, evaluating the technical aspects of the lab-scale models, refining how the technology will be used, assessing the comparative value and integrating the inputs of innovator actors.
The creative cliff illusion – people assume that their creativity will drop over time. This study however demonstrates that this is not the case and that having such negative assumptions can be detrimental to performance.
The authors introduced their article with 4 quotes, which then anchored the different perspectives to explore immigration.
Self-selection among immigrants and role in the diffusion of innovation
“Migration has one characteristic that should make it very effective as a diffusion method. The hardships occasioned with [it] will usually discourage all but the most resourceful, energetic, and courageous. Those who have the hardihood to venture in this way hence are likely to have exactly those human qualities which are most essential to innovating and diffusing”
-Warren C. Scoville (“Spread of Techniques: Minority Migrations and the Diffusion of Technology”, Journal of Economic History 1951: 11/4, p.349)
Arguments against brain-drain and for the value of choice
“… even were it possible to force the professionals to stay at home, it would be a foolish policy. Lack of congenial working conditions, absence of peer professionals to interact with, and resentment at being deprived of the chance to emigrate can lead to a wholly unproductive situation in which one has the body but not the brain. The brain is not a static thing: it can drain away faster sitting in the wrong place than when travelling to Cambridge or Paris!”
Jagdish Bhagwati (In Defense of Globalisation, Oxford University Press: 2007; p.214)
Struggles in assimilating and in being away
“Le véritable lieu de naissance est celui où l’on a porté pour la première fois un coup d’oeil intelligent sur soi-même: mes premières patries ont été des livres, à un moindre degré, des écoles.” (The real birthplace is where you first took an intelligent look at yourself: my first countries were books, to a lesser extent, schools.)
“We hire from the best schools. All the people who go to those schools […] we offer jobs to American, non-American, that’s who we build these product teams around. And so, because we’re in a very competitive business, we don’t compromise on that. Wherever we can get those people, that’s where we create the jobs.”
Bill Gates (National Public Radio interview, March 12, 2008; https://www.npr.org/transcripts/88154016– last visit May 2020)
It has been quite a while since I’ve updated my blog. I was busy with finishing my PhD and securing my postdoc position. I’m still pursuing academia for now and thus, would still have to continue reading the literature for the latest advances in the management sciences. These are my interesting reads of the week.
Disruption Versus Discontinuity: Definition and Research Perspective From Behavioral Economics – I have to admit that I use the terms disruption and discontinuity interchangeably. This articles explains the difference between the two. Discontinuity refers to when a new technology competes directly with an established one based on having better performance on some technological dimension (typically 10x better). On the other hand, disruptions attach dominant technologies by satisfying customer needs even though they may not be performing as well on this primary dimension.
Anchor entrepreneurship and industry catalysis: The rise of the Italian Biomedical Valley – fascinating account on the role of entrepreneurship in transforming a depressed rural area into an internationally known medical-device cluster. I especially like how much they take into account the role of luck in the story of this entrepreneur Mario Veronesi: “many of Veronesi’s successes came accidentally, a result of serendipity, being present at the dawn of an emerging medical field that married knowledge about renal and cardiac treatment to improved plastics.”
From creative destruction to creative appropriation: A comprehensive framework – study exploring Didi, usually called China’s Uber. I appreciated the typology in the paper talking about the other forms of creative destruction. Destruction is when a firm outright does not cooperate with the incumbents. Creative cooperation is when incumbents work together with the disruptors. In the middle of these two is creative appropriation, where a firm disrupts a market by leveraging the complementary resources of an incumbent without directly cooperating with them.
I needed to familiarize myself with the literature on science entrepreneurship (for reasons I’m going to explain soon). After delving into bibliometrics and doing literature review repetitively for my PhD, I already have a system to efficiently introduce myself to a new literature. In this post, I will explain my process, hoping it helps others who are also entering a new field.
I typically follow these steps:
Explore the Web of Knowledge using a keyword search
Explore data in Python
Create visualizations using VosViewer
The first step for me is usually just trying out different keywords in the Web of Knowledge. I then browse the first page of the latest articles and the top cited articles. I try to check whether these are related to my topic of interest.
For this topic of science entrepreneurship, I settled with the following keywords. I also narrowed it down to the management journals that I know are relevant to technology and innovation management and just general management. Moreover, I was just interested in the papers published from 2010. Below was my keyword search:
TS=(science OR technology ) AND TS=(startup* OR “start up” OR “new venture” OR entrepreneur* OR “new firm” OR “spin off” OR spinoff* OR SME OR SMEs) AND SO=(RESEARCH POLICY OR R D MANAGEMENT OR STRATEGIC MANAGEMENT JOURNAL OR JOURNAL OF PRODUCT INNOVATION MANAGEMENT OR ACADEMY OF MANAGEMENT REVIEW OR ACADEMY OF MANAGEMENT JOURNAL OR TECHNOVATION OR SCIENTOMETRICS OR TECHNOLOGICAL FORECASTING “AND” SOCIAL CHANGE OR TECHNOLOGY ANALYSIS STRATEGIC MANAGEMENT OR ORGANIZATION SCIENCE OR ADMINISTRATIVE SCIENCE QUARTERLY OR JOURNAL OF BUSINESS VENTURING OR INDUSTRY “AND” INNOVATION OR STRATEGIC ENTREPRENEURSHIP JOURNAL OR JOURNAL OF TECHNOLOGY TRANSFER OR JOURNAL OF ENGINEERING “AND” TECHNOLOGY MANAGEMENT OR JOURNAL OF MANAGEMENT OR JOURNAL OF MANAGEMENT STUDIES OR RESEARCH TECHNOLOGY MANAGEMENT OR ENTREPRENEURSHIP THEORY “AND” PRACTICE OR ACADEMY OF MANAGEMENT ANNALS OR ACADEMY OF MANAGEMENT PERSPECTIVES OR JOURNAL OF BUSINESS RESEARCH OR BRITISH JOURNAL OF MANAGEMENT OR EUROPEAN JOURNAL OF MANAGEMENT OR MANAGEMENT SCIENCE)
After exploring the results, I then downloaded the articles. These amounted to 1412 articles in total. Since WOS only allowed downloading of 500 at a time, I named these files 1-500.txt, 501-1000.txt and so on. I saved all the files in a folder (named Raw in this case) in my computer.
Data Exploration in Python
In the following, I show the code to import the data into Python and format the articles into a pandas dataframe.
import re, csv, os
import pandas as pd
import numpy as np
import nltk
import math
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style('white')
from collections import Counter
columnnames =['PT','AU','DE', 'AF','TI','SO','LA','DT','ID','AB','C1','RP','EM','CR','NR','TC','U1','PU','PI','PA','SN','EI','J9','JI','PD','PY','VL','IS','BP','EP','DI','PG','WC','SC','GA','UT']
def convertWOScsv(filename):
openfile = open(filename, encoding='latin-1')
sampledata = openfile.read()
# divide into list of records
individualrecords = sampledata.split('\n\n')
databaseofWOS = []
for recordindividual in individualrecords:
onefile = {}
for x in columnnames:
everyrow = re.compile('\n'+x + ' ' + '((.*?))\n[A-Z][A-Z1]', re.DOTALL)
rowsdivision = everyrow.search(recordindividual)
if rowsdivision:
onefile[x] = rowsdivision.group(1)
databaseofWOS.append(onefile)
return databaseofWOS
def massconvertWOS(folder):
publicationslist = []
for file in os.listdir(folder):
if file.endswith('.txt'):
converttotable = convertWOScsv(folder + '\\' + file)
publicationslist += converttotable
publicationslist = pd.DataFrame(publicationslist)
publicationslist.dropna(how='all', inplace=True)
publicationslist.reset_index(drop=True, inplace=True)
publicationslist['PY'] =publicationslist['PY'].fillna('').replace('', '2019').astype(int)
publicationslist['TC'] = publicationslist['TC'].apply(lambda x: int(x.split('\n')[0]))
return publicationslist
df = massconvertWOS('Raw')
df = df.drop_duplicates('UT').reset_index(drop=True)
I preview some of the articles that I was able to download below. I chose the relevant columns to show.
print('Number of Articles:', df.shape[0])
df.head()[['TI', 'AU', 'SO', 'PY']]
Number of Articles: 1412
TI
AU
SO
PY
0
Non-linear effects of technological competence…
Deligianni, I\n Voudouris, I\n Spanos, Y\n…
TECHNOVATION
2019
1
Creating new products from old ones: Consumer …
Robson, K\n Wilson, M\n Pitt, L
TECHNOVATION
2019
2
What company characteristics are associated wi…
Koski, H\n Pajarinen, M\n Rouvinen, P
INDUSTRY AND INNOVATION
2019
3
Through the Looking-Glass: The Impact of Regio…
Vedula, S\n York, JG\n Corbett, AC
JOURNAL OF MANAGEMENT STUDIES
2019
4
The role of incubators in overcoming technolog…
Yusubova, A\n Andries, P\n Clarysse, B
R & D MANAGEMENT
2019
WOS is smart in the sense that even if the text does not contain the keywords you said, they still may include papers because they sense that these are relevant papers. To filter out these papers that did not contain the keywords I wanted, I further filtered the dataset by checking the title, abstract and author-selected keywords. Moreover, let’s remove articles without any citations.
df["txt"] = df["TI"].fillna("") + " " + df["DE"].fillna("") + " " + df["AB"].fillna("")
df["txt"] = df["txt"].apply(lambda x: x.replace('-', ' '))
df = df[df['txt'].apply(lambda x: any([y in x.lower() for y in ['scien', 'technolog']]))]
df = df[df['txt'].apply(lambda x: any([y in x.lower() for y in ['startup', 'start up', 'new venture', 'entrepreneur', 'new firm', 'spin off',
'spinoff', 'sme ', 'smes ']]))]
df = df[~df['CR'].isnull()]
print('Number of Articles:', df.shape[0])
I can look at the top cited articles. This shows what are the foundational material that I should know before delving into the topic.
topcited = df['CR'].fillna('').apply(lambda x: [y.strip() for y in x.split('\n')]).sum()
pd.value_counts(topcited).head(10)
COHEN WM, 1990, ADMIN SCI QUART, V35, P128, DOI 10.2307/2393553 115
Shane S, 2004, NEW HORIZ ENTREP, P1 88
Shane S, 2000, ACAD MANAGE REV, V25, P217, DOI 10.5465/amr.2000.2791611 87
Rothaermel FT, 2007, IND CORP CHANGE, V16, P691, DOI 10.1093/icc/dtm023 86
BARNEY J, 1991, J MANAGE, V17, P99, DOI 10.1177/014920639101700108 81
Shane S, 2000, ORGAN SCI, V11, P448, DOI 10.1287/orsc.11.4.448.14602 78
TEECE DJ, 1986, RES POLICY, V15, P285, DOI 10.1016/0048-7333(86)90027-2 77
Di Gregorio D, 2003, RES POLICY, V32, P209, DOI 10.1016/S0048-7333(02)00097-5 77
EISENHARDT KM, 1989, ACAD MANAGE REV, V14, P532, DOI 10.2307/258557 75
Nelson R.R., 1982, EVOLUTIONARY THEORY 69
dtype: int64
The articles above are not really very specific to our topic of interest. These are foundational papers in innovation/management. To explore those papers that are more relevant to our topic, what I can do then is find which is the most cited within the papers in this dataset, meaning hey include the keywords that I’m interested in. This is the internal citation of the papers.
def createinttc(df):
df["CRparsed"] = df["CR"].fillna('').str.lower().astype(str)
df["DI"] = df["DI"].fillna('').str.lower()
df["intTC"] = df["DI"].apply(lambda x: sum([x in y for y in df["CRparsed"]]) if x!="" else 0)
df["CRparsed"] = df["CR"].astype(str).apply(lambda x: [y.strip().lower() for y in x.split('\n')])
return df
df = createinttc(df).reset_index(drop=True)
A complementary approach is to look at the articles that are citing the most the rest of the papers in the dataset. These allows us to see which reviews already integrates the studies within our dataset. We can then start reading from this set of papers as they cover already a lot of the other papers in the dataset.
doilist = [y for y in df['DI'].dropna().tolist() if y!='']
df['Citing'] = df['CR'].apply(lambda x: len([y for y in doilist if y in x]))
df.sort_values('Citing', ascending=False)[['TI', 'AU', 'SO' , 'PY', 'Citing', ]].head(10)
TI
AU
SO
PY
Citing
139
Conceptualizing academic entrepreneurship ecos…
Hayter, CS\n Nelson, AJ\n Zayed, S\n O’C…
JOURNAL OF TECHNOLOGY TRANSFER
2018
75
168
THE PSYCHOLOGICAL FOUNDATIONS OF UNIVERSITY SC…
Hmieleski, KM\n Powell, EE
ACADEMY OF MANAGEMENT PERSPECTIVES
2018
33
138
Re-thinking university spin-off: a critical li…
Miranda, FJ\n Chamorro, A\n Rubio, S
JOURNAL OF TECHNOLOGY TRANSFER
2018
31
122
Public policy for academic entrepreneurship in…
Sandstrom, C\n Wennberg, K\n Wallin, MW\n …
JOURNAL OF TECHNOLOGY TRANSFER
2018
28
37
Opening the black box of academic entrepreneur…
Skute, I
SCIENTOMETRICS
2019
28
166
RETHINKING THE COMMERCIALIZATION OF PUBLIC SCI…
Fini, R\n Rasmussen, E\n Siegel, D\n Wik…
ACADEMY OF MANAGEMENT PERSPECTIVES
2018
25
68
The technology transfer ecosystem in academia….
Good, M\n Knockaert, M\n Soppe, B\n Wrig…
TECHNOVATION
2019
24
40
Theories from the Lab: How Research on Science…
Fini, R\n Rasmussen, E\n Wiklund, J\n Wr…
JOURNAL OF MANAGEMENT STUDIES
2019
22
659
How can universities facilitate academic spin-…
Rasmussen, E\n Wright, M
JOURNAL OF TECHNOLOGY TRANSFER
2015
21
73
Stimulating academic patenting in a university…
Backs, S\n Gunther, M\n Stummer, C
JOURNAL OF TECHNOLOGY TRANSFER
2019
21
Bibliometric Analysis in VosViewer
To create visualizations of the paper, we do the following steps. First, we can export the filtered dataset into a text file.
def convertWOStext(dataframe, outputtext):
dataframe["PY"]=dataframe["PY"].astype(int)
txtresult = ""
for y in range(0, len(dataframe)):
for x in columnnames:
if dataframe[x].iloc[y] != np.nan:
txtresult += x + " " + str(dataframe[x].iloc[y]) + "\n"
txtresult += "ER\n\n"
f = open(outputtext, "w", encoding='utf-8')
f.write(txtresult)
f.close()
convertWOStext(df, 'df.txt')
We can then open the file in VosViewer. From there, we can create various visualizations. I like using bibliographic coupling to map all the papers in the dataset
I saved the file in VosViewer. This gives you two files, one has the data on each document and the second file has the network data. We modify these files to make certain changes. First, the citations above reflect their citations from all the papers outside the dataset. I want the internal citations to be shown so I replace it.
The above network just uses the citation data of the publications. To improve it, I like integrating the textual data from the title, abstract and keywords. I followed the steps suggested here for cleaning the text (https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/). I then combine these two measures to allow for hybrid clustering
Liu, Xinhai, Shi Yu, Frizo Janssens, Wolfgang Glänzel, Yves Moreau, and Bart De Moor. “Weighted hybrid clustering by combining text mining and bibliometrics on a large‐scale journal database.” Journal of the American Society for Information Science and Technology 61, no. 6 (2010): 1105-1119.
#Bibliometric coupling
from scipy.sparse import coo_matrix
from collections import Counter
from sklearn.metrics.pairwise import cosine_similarity
def createbibnet(df):
allsources = Counter(df['CRparsed'].sum())
allsources = [x for x in allsources if allsources[x]>1]
dfcr = df['CRparsed'].reset_index(drop=True)
dfnet = []
i=0
for n in allsources:
[dfnet.append([i, y]) for y in dfcr[dfcr.apply(lambda x: n in x)].index]
i+=1
dfnet_matrix = coo_matrix(([1] * len(dfnet), ([x[1] for x in dfnet], [x[0] for x in dfnet])),
shape=(dfcr.shape[0], len(allsources)))
return cosine_similarity(dfnet_matrix, dfnet_matrix)
#Lexical Coupling
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
import string
from gensim.models.phrases import Phrases, Phraser
def clean(doc):
stop = set(stopwords.words('english'))
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = ''.join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
normalized = " ".join([x for x in normalized.split() if not any(c.isdigit() for c in x)])
normalized = " ".join([x for x in normalized.split() if len(x)>3])
return normalized
def bigrams(docs):
phrases = Phrases(docs)
bigram = Phraser(phrases)
docs = docs.apply(lambda x: bigram[x])
phrases = Phrases(docs)
trigram = Phraser(phrases)
docs = docs.apply(lambda x: trigram[x])
return docs
def createtfidf(df, sheet_name):
df["lemma"] = df["txt"].apply(lambda x: clean(x).split())
df["lemma"] = bigrams(df["lemma"])
vect = TfidfVectorizer(min_df=1)
tfidftemp = vect.fit_transform([" ".join(x) for x in df["lemma"]])
return cosine_similarity(tfidftemp)
#Hybrid network
def createhybridnet(df, weightlex, sheet_name='Sheet1'):
bibnet = createbibnet(df)
tfidftemp = createtfidf(df, sheet_name)
hybnet = pd.DataFrame(np.cos((1-weightlex) * np.arccos(bibnet) + weightlex * np.arccos(tfidftemp))).fillna(0)
return hybnet
from itertools import combinations
def createvosviewer2filefromhybrid(hybridlexcit, minimumlink, outputfilename):
forvisuals = []
for x, y in combinations(hybridlexcit.index, 2):
val = int(hybridlexcit.loc[x,y]*100)
if val > minimumlink:
forvisuals.append([x, y, val])
forvisuals = pd.DataFrame(forvisuals)
forvisuals[0] = forvisuals[0] + 1
forvisuals[1] = forvisuals[1] + 1
forvisuals.to_csv(outputfilename, index=False, header=False)
dfhybrid = createhybridnet(df, 0.5)
createvosviewer2filefromhybrid(dfhybrid, 0, r'Processed/VosViewer_2_Hybrid.txt')
If we reimport these modified files to VosViewer. We come up with this visualization which incorporates both textual and citation data.
I can then spend tons of time just exploring the network. I look at the papers in each cluster. I check which papers have high citations. I can do this also with the help of python. We can update the clustering using the one generated by VosViewer.
Discoverers in scientific citation data – this research finds that there are a group of researchers who are good at discovering (or citing early) potentially important papers. This reminds me of the book Superforecasting which talks about how some people are better than others in forecasting the future.
Collaborative patents and the mobility of knowledge workers – In my field of FBDD, research mobility seems to be one of the most important mechanisms for the knowledge to spread. In this study of the European biotech sector, inventors who were previously located together are found to form collaborations faster.
Exploration versus exploitation in technology firms: The role of compensation structure for R&D workforce – people respond to incentives. This study explores how a firm can structure its incentives as a lever to incentivize exploration / exploitation. In this study, the researchers find that firms with ” higher-powered tournament incentives in vertical compensation structure report higher fraction of innovation directed towards exploration”
Improving the peer review process: a proposed market system – Currently, reviewers do not receive any compensation given the amount of work they have to do. This is bad for science as well because papers do not get reviewed properly/fast enough. Creating a market system for the review process for better incentivization of both authors and reviewers might improve the process.
Federal funding of doctoral recipients: What can be learned from linked data – New datasets are always exciting. Researchers in this study propose linking a huge dataset on university payrolls with another huge survey about PhD graduates. It would be interesting to see how other researchers will use data to understand innovation, basic research, career development to name a few.